Data-Juicer: A One-Stop Data Processing System for Large Language Models
Paper • 2309.02033 • Published • 4
Our first data-centric LLM competition begins! Please visit the competition's official websites, FT-Data Ranker (1B Track, 7B Track), for more information.
This is a reference LLM from Data-Juicer.
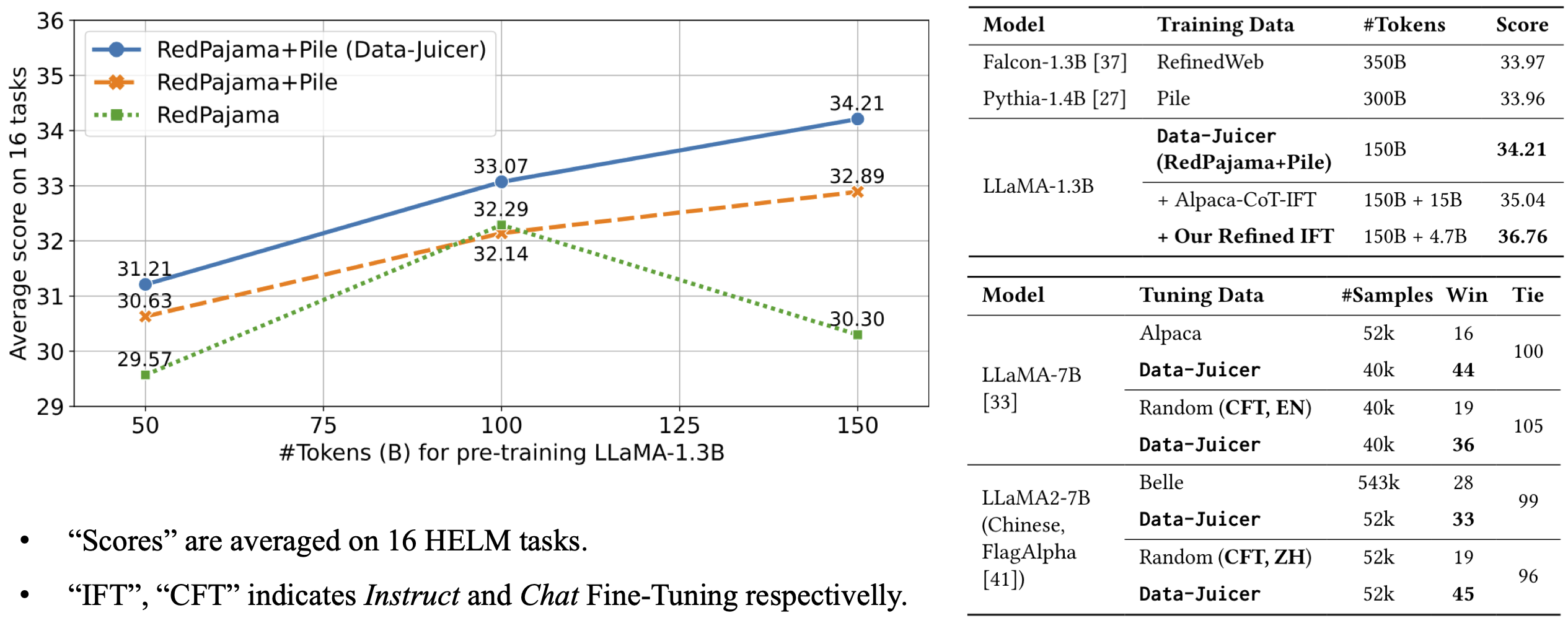
The model architecture is LLaMA-1.3B and we adopt the OpenLLaMA implementation. The model is pre-trained on 100B tokens of Data-Juicer's refined RedPajama and Pile. It achieves an average score of 33.07 over 16 HELM tasks, beating LLMs trained on original RedPajama and Pile datasets.
For more details, please refer to our paper.