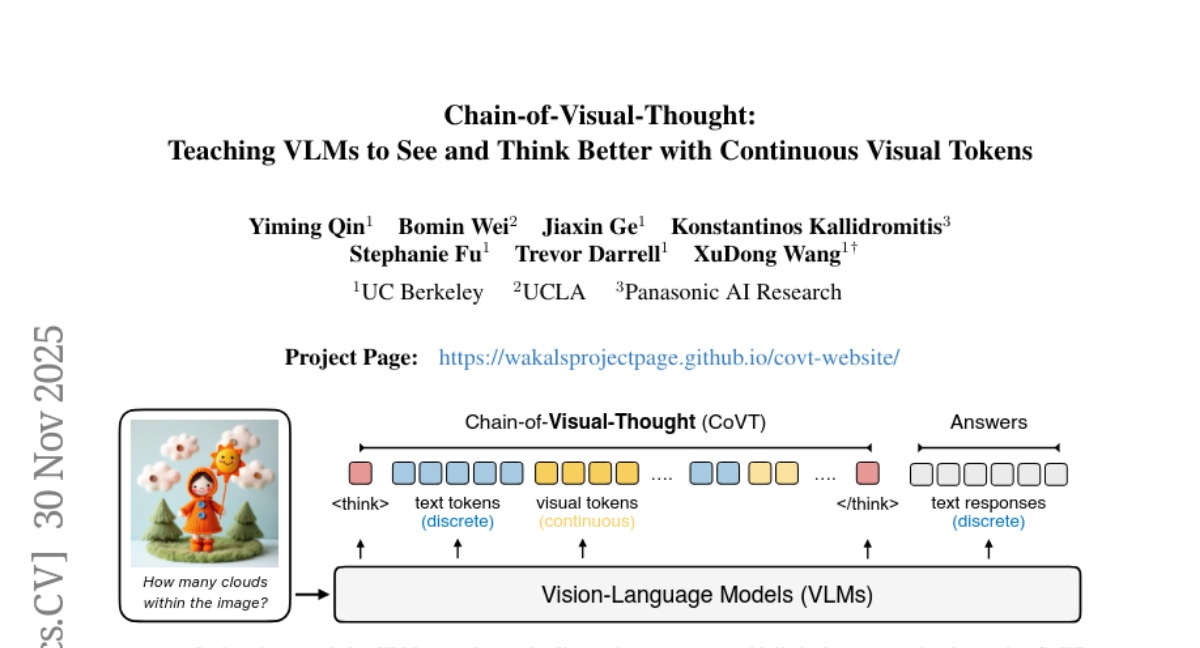
Enrich VLMs’ vision-centric reasoning capabilities via Chain-of-Visual-Thought!
YM Qin
Wakals
AI & ML interests
Computer Vision, Vision-language Model, Generative Model
Recent Activity
upvoted a paper about 3 hours ago
Emu3.5: Native Multimodal Models are World Learners upvoted a paper about 22 hours ago
dLLM: Simple Diffusion Language Modeling liked
a dataset 2 days ago
DietCoke4671/BlenderBench Organizations
None yet